


Overfitting and underfitting can be said to be one of the greatest challenges that developers encounter when constructing artificial intelligence systems. These two issues arise when a machine learning model does not learn patterns from data in the appropriate manner. Consequently, the model either overlearns the training data or learns insufficiently to make useful predictions.
- What Are Machine Learning Errors in AI Models?
- Understanding Overfitting and Underfitting in Deep Learning
- Overfitting and Underfitting Explained
- Overfitting: When the Model Learns Too Much
- Underfitting: When the Model Learns Too Little
- The Bias-Variance Problem in Machine Learning
- Common Causes of Model Overfitting
- 1. Extremely Complex Neural Networks
- 2. Small Training Datasets
- 3. Training for Too Many Epochs
- 4. Too Many Model Parameters
- 5. Noisy Training Data
- Why Underfitting Happens When Training Models for AI
- Techniques to Prevent Overfitting in Deep Learning Optimization
- Regularization Techniques
- Dropout Layers
- Data Augmentation
- Early Stopping
- Cross Validation
- Increasing Dataset Size
- How to Fix Underfitting When Training Models for AI
- Increase Model Complexity
- Train the Model Longer
- Add Better Features
- Reduce Regularization
- Use More Advanced Architectures
- Overfitting vs Underfitting: Key Differences
- Why Understanding Overfitting and Underfitting Matters in AI Development
- Conclusion
The concept of overfitting and underfitting is a fundamental concept of machine learning or deep learning. The problems have a direct effect on model accuracy, reliability, and performance in the real world. The training of the models’ AI engineers needs to be thoughtful to maintain the balance of model learning to ensure that the model is not only good at the training data but also can do well with the new, unexplored data.
We are going to discuss what overfitting and underfitting are, what causes them, their connection to the bias-variance problem, and the practical methods of addressing them in deep learning optimization.
Related: AI vs Traditional Healthcare: How Medical Technology Is Changing
What Are Machine Learning Errors in AI Models?
Machine learning models acquire knowledge based on data. The algorithm studies examples during the training phase to change its internal parameters so that it can make correct predictions.
Although data-driven learning is not always ideal. Errors in models are referred to as machine learning errors. These mistakes usually occur when a model does not generalize the patterns in which it was trained in an appropriate manner.
Ideally, a model is supposed to detect meaningful patterns, which can be applied to new data. However, in case of the learning process failure, the model either memorizes the training data too tightly or does not capture the patterns at all.
Here is where overfitting and underfitting are also critical in the development of AI.
These two issues cause the performance of the models to be lower, and predictions become unreliable. It is important to learn how they happen to optimize deep learning and develop superior AI systems.
Understanding Overfitting and Underfitting in Deep Learning
Overfitting and Underfitting Explained
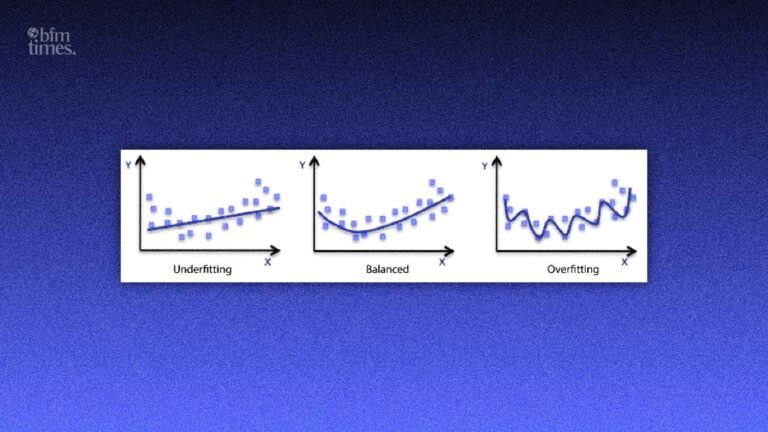
Overfitting and underfitting in deep learning entail two contrasting learning characteristics.
A model is supposed to make sense of significant patterns without memorizing the data or leaving out significant information. In the failure of this balance, the models will either overfit or underfit the data.
Overfitting: When the Model Learns Too Much
Model overfitting is when a machine learning model is learned too well to include noise, random variations, and irrelevant patterns in the training data.
The model does not extract the general patterns, but it memorizes the training dataset.
Key Characteristics of Model Overfitting
- Very high training accuracy
- Weak performance on unfamiliar or unknown information.
- Lack of generalization skills.
- Extremely complex model behavior.
To illustrate this, a student who has to memorize answers in practice tests but would not understand the concepts can be a case in point. The student will do very well in the practice test and fail to cope with new questions in the actual test.
Similarly, model overfitting causes a machine learning model to perform extremely well on training data but fail when applied to real-world data.
This is among the most frequent machine learning errors during AI system training.
Underfitting: When the Model Learns Too Little
Extrapolation underfitting is the converse of overfitting. It occurs when the model is too simple to explain the underlying pattern of the data.
The model does not learn meaningful relationships; instead, it does not learn the data structure.
Key Characteristics of Underfitting
- Low training accuracy
- Low testing accuracy
- Model too simple
- Insufficient learning
As an illustration, consider the case of house prices, whereby the prediction outcomes are based on the size of the house without any reference to the location, the number of rooms, or the proximity to amenities. There is insufficient information in the model to come up with accurate predictions.
Overfitting and underfitting, in this instance, illustrate the fact that learning behavior may be wrong and cause poor model performance.
The Bias-Variance Problem in Machine Learning
The bias-variance problem explains why overfitting and underfitting occur when training machine learning models.
The prediction errors, which affect the learning of a model, are bias and variance.
High Bias → Underfitting
Bias denotes the extent to which a model issues assumptions against the data. In the case of high bias in a model, it simplifies the learning process.
High bias typically causes underfitting, as the model is not able to model some complicated patterns in the data.
High Variance → Overfitting
Variance is used to assess the sensitivity of a model to training data. In case the variance is excessive, the model is highly susceptible to slight changes in the data.
This results in overfitting of the models, where the model learns the training data instead of learning a generalized pattern.
Effective AI models are highly sensitive to bias and variance so that they attain consistent and dependable forecasts. One of the main components of deep learning optimization is this balance.
Common Causes of Model Overfitting
Model overfitting in deep learning model training occurs due to a few reasons.
1. Extremely Complex Neural Networks
In the case of neural networks with excessive layers or parameters, the model is free to memorize the data instead of acquiring relevant patterns.
2. Small Training Datasets
Small datasets enhance the chances of overfitting and underfitting. Models can also memorize random noise rather than general patterns with fewer examples.
3. Training for Too Many Epochs
Excessive model training may also result in the model memorizing training data rather than learning any useful relationships.
4. Too Many Model Parameters
Big models that have too many parameters usually reproduce unneeded information in the data that is overfit.
5. Noisy Training Data
There is usually irrelevant or erroneous information in datasets. It results in machine learning errors and poor prediction quality.
These are problems that directly affect deep learning optimization and should be taken into consideration.
Why Underfitting Happens When Training Models for AI
Whereas overfitting occurs because of overlearning, underfitting occurs when the model fails to learn enough according to the data.
There are a number of reasons that lead to underfitting when training models for AI systems.
Simple Model Architecture
In the event that the model is overly simplistic, then it may not be able to relate to the data.
Insufficient Training Time
It is because by training a model with too few epochs, it does not learn important patterns.
Poor Feature Selection
In the event that critical features are not available, the model does not have the information required to make reasonable forecasts.
Excessive Regularization
Regularization methods assist in avoiding overfitting, although when used too forcefully, they can restrict the learning of the model.
Knowledge of overfitting and underfitting can assist the engineer in modifying such factors when optimizing deep learning.
Suggested: Best AI Tools for Crypto Trading
Techniques to Prevent Overfitting in Deep Learning Optimization
The problem of preventing model overfitting is extremely important in the development of effective AI systems. A number of methods are employed by engineers to enhance deep learning optimization.
Regularization Techniques
The regularization introduces constraints to model parameters, which avoids the model becoming too complex.
Dropout Layers
Neurons are randomly disabled during training by dropout. This compels the model to acquire generalized patterns.
Data Augmentation
Data augmentation augments data by creating variations of available data. This minimizes the possibility of overfitting and underfitting.
Early Stopping
Early stopping checks the performance of validation and terminates training once the model starts overfitting.
Cross Validation
Cross-validation is used to test the model on several data subsets to provide a good generalizing model.
Increasing Dataset Size
Additional information will enable the model to train on wider patterns and minimize errors in machine learning.
How to Fix Underfitting When Training Models for AI
Underfitting can be solved by enhancing the capacity of the model to discover complex patterns.
In the training models AI, a designer usually employs the following solutions.
Increase Model Complexity
The model can be built using deeper neural networks to capture more complex relationships.
Train the Model Longer
The more training epochs, the more patterns the model will learn using the dataset.
Add Better Features
The feature engineering will assist the model in getting more valuable information.
Reduce Regularization
It is possible to reduce the strength of regularization to enable the model to learn in a more liberal manner.
Use More Advanced Architectures
More sophisticated neural networks are usually able to enhance the learning process and minimize machine learning errors.
The methods aid in balance and decrease overfitting and underfitting in the process of optimization of deep learning.
Overfitting vs Underfitting: Key Differences
Developers are able to diagnose problems with models much faster by being aware of the difference between overfitting and underfitting.
Understanding the differences between overfitting and underfitting helps developers diagnose model problems quickly.
| Factor | Overfitting | Underfitting |
| Model Complexity | Too complex | Too simple |
| Training Accuracy | Very high | Low |
| Testing Accuracy | Poor | Poor |
| Bias | Low bias | High bias |
| Variance | High variance | Low variance |
Machine learning aims at reaching a compromise between the two extremes. An effective model ought to be consistent in the training and unseen data.
This balance is the core objective of deep learning optimization.
Also Read: Convolutional Neural Networks (CNN) Explained
Why Understanding Overfitting and Underfitting Matters in AI Development
To create a dependable artificial intelligence system, a person should understand overfitting and underfitting.
The developers of AI should be cautious about the manner in which models learn to come up with correct predictions.
The principles assist engineers:
- Enhance the accuracy of prediction.
- Minimize the errors of machine learning.
- Create machine learning systems that are scalable.
- Streamline AI training processes.
The ideas are applicable in most fields, like natural language processing, recommendation systems, financial forecasting, and computer vision.
In every case, balancing learning behavior is critical when training an AI model.
Conclusion
Overfitting and underfitting are two of the most relevant issues in training machine learning models in the current development of artificial intelligence.
When models learn the training data too well, it is overfitting, and when models cannot learn meaningful patterns, it is underfitting. The two issues are directly related to the bias-variance problem, which contributes to the learning behavior in connection with the model complexity.
The most effective AI systems are about a balance between the quality of the datasets, model complexity, and training strategies. With the appropriate methods used in the optimization of deep learning, engineers will be able to minimize machine learning errors and create models that can work with actual data.
Finally, understanding the problem of overfitting and underfitting enables developers to develop smarter, more accurate, and scalable AI systems that can be used to solve real-world problems.
Disclaimer: BFM Times acts as a source of information for knowledge purposes and does not claim to be a financial advisor. Kindly consult your financial advisor before investing.
What is overfitting in deep learning?
Overfitting occurs when a model learns the training data too closely and performs poorly on new, unseen data.
What is underfitting in deep learning?
Underfitting happens when a model is too simple to capture patterns in the data and gives inaccurate predictions.
How can overfitting and underfitting be prevented?
Techniques like regularization cross validation better datasets and model tuning help balance model performance.







{kind=link}