


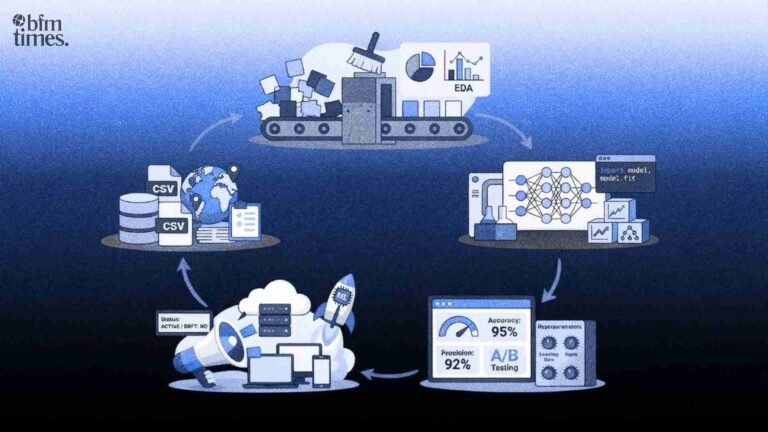
Building machine learning today isn’t about writing a few lines of code and hoping for magic. If you’ve ever tried to build ML models in a real-world setting, you already know that it’s messy, iterative, and highly dependent on how well you understand the problem. This guide is not a theoretical discussion; it is a description of the actual process.
- Building ML Models Is Not About Code: It’s About the Process
- Before You Start: Understanding the Problem Changes Everything
- Step-by-Step Process to Build ML Models
- Step 1: Data Collection: The Foundation of Every Model
- Step 2: Data Cleaning & Preparation
- Step 3: Exploratory Data Analysis (EDA)
- Step 4: Feature Engineering
- Step 5: Choosing the Right Model
- Step 6: Training the Model
- Step 7: Model Evaluation
- Step 8: Model Tuning & Optimization
- Step 9: Deployment & Real-World Use
- Tools You Need to Build ML Models
- Python & Libraries: The Core of ML Development
- Jupyter Notebook: Best for Experimentation
- Cloud Platforms: Scaling ML Models
- ML Model Development Is Iterative, Not Linear
- Common Mistakes Beginners Make When Building ML Models
- How Real Companies Build ML Models
- The Future of ML Model Development
- Building ML Models Is a Skill, Not a Step List
- Frequently Asked Questions
Building ML Models Is Not About Code: It’s About the Process
Most beginners assume machine learning = coding + algorithms. However, in actuality, programming is only a part of the picture. Knowing all the available algorithms is useless; built ML models do not work in practice.
It’s the thinking part that really counts. Your problem formulation, data quality, and result iteration outweigh your algorithm choice. Many machine learning projects fail due to a poor foundation.
The very attempt to develop a machine learning algorithm can be ruined by poor data quality, unclear objectives, or false hopes before the process even starts.
At its core, learning how to build ML models means learning how to think in systems: defining problems clearly, validating assumptions, and continuously improving outcomes.
Before You Start: Understanding the Problem Changes Everything
Even before picking up a notebook or writing code in Python, you should have some clarity about things. Could you please clarify exactly what it is that you aim to solve?
Do you want to predict customer churn? Are you trying to detect fraud? Or do you want to recommend products? Every problem requires a different set of assumptions, data requirements, and evaluation criteria. Without an objective, your model won’t know which way to go.
The outcomes of machine learning models are just as significant as the data used to create them. Are you trying to predict a continuous numerical value? A categorical value? Or perhaps something even more complicated?
And the key lesson here is this: When you have incorrectly formulated the problem, you will not get an incorrect solution but an unusable one.
Step-by-Step Process to Build ML Models
Step 1: Data Collection: The Foundation of Every Model
Data serves as the foundation for all machine learning projects, but not every dataset is suitable for training a machine learning model. In general, when developing machine learning models, the quality of the dataset used is more important than its quantity.
Datasets must mimic real-life situations. Otherwise, the output generated by the machine learning models will not make sense. Therefore, much effort goes into gathering high-quality datasets from different sources, such as databases or APIs, or manually creating them.
Key focus:
- Reliable and consistent data sources
- Sufficient volume for learning patterns
- Real-world representation
Step 2: Data Cleaning & Preparation
The raw dataset itself is disorganized. Inconsistencies like missing values, format issues, and duplications are typical. If you neglect to clean, your algorithm learns from nonsense.
When you build ML models, the preprocessing phase is often where real improvements kick in. In this phase, you ensure the usability of your data.
Key tasks:
- Handling missing values
- Encoding categorical variables
- Normalization and scaling
Step 3: Exploratory Data Analysis (EDA)
However, before building the model, it is important to understand the data. This is the stage at which trends and patterns become apparent.
The process is more of an investigation than using tools. What makes those numbers take a certain distribution? Are there any associations between variables? Are there any outliers that could bias the output?
If you’re serious about learning how to create ML models, EDA is where intuition develops.
Key tasks:
- Data visualization
- Correlation analysis
- Anomaly detection
Step 4: Feature Engineering
Here’s where good average models turn into great ones. The process of “feature engineering” transforms raw data into useful inputs for training the model.
Feature engineering is one of the most critical phases in the process of creating machine learning models, and often, it is more important than choosing the right algorithm.
Key focus:
- Selecting relevant features
- Creating new variables
- Removing irrelevant noise
Step 5: Choosing the Right Model
There is no best algorithm, only an algorithm that suits your particular problem. When you build ML models, it will depend on what type of data you have.
Linear models typically perform exceptionally well for structured data. Neural networks are superior choices when dealing with complex data, like texts or images.
Options include:
- Regression models
- Decision trees and ensembles
- Neural networks
Step 6: Training the Model
The training process is the one where the model will begin to learn from the dataset. However, training doesn’t involve just calling the .fit() method; you need to define what parameters you want your model to learn.
These include the size of your dataset, the number of iterations, and the minimization of loss/error. At this stage, experimentation is inevitable.
In practice, when teams develop machine learning algorithms, they don’t get everything right in one iteration.
Important aspects:
- Training dataset selection
- Iterations and epochs
- Loss minimization
Step 7: Model Evaluation
A model that performs well on training data might fail in real life. That’s why evaluation is critical.
Evaluating the model through unseen data will tell you whether it’s capable of learning or not. By doing so, you ensure your model learns things rather than just memorizing them.
In any comprehensive guide to machine learning models, evaluation is what separates experimentation from production readiness.
Metrics include:
- Accuracy
- Precision and recall
- F1-score
Step 8: Model Tuning & Optimization
Improvements are possible even for models that work well. In tuning, you fine-tune your model’s performance by tweaking parameters.
Tuning hyperparameters helps achieve better accuracy, but it comes at the cost of time. And that’s why there are methods such as grid search and cross-validation.
When you build ML models, optimization is often what pushes your model from “decent” to “production-ready.”
Methods:
- Grid search
- Cross-validation
Step 9: Deployment & Real-World Use
A model becomes valuable only when it goes live. This is the point where it begins engaging with actual users and real data.
Deploying a model means packaging it in APIs, embedding it in applications, and tracking its performance.
Modern ML step-by-step workflows tightly connect deployment with monitoring and updates.
Includes:
- API integration
- Cloud deployment
- Performance monitoring
Tools You Need to Build ML Models
Python & Libraries: The Core of ML Development
Python reigns supreme in the world of ML because it is straightforward, easy to use, and has a huge user base.
Libraries like TensorFlow, PyTorch, and Scikit-learn make it easier to build ML models without reinventing the wheel. They handle complex computations, letting you focus on logic and experimentation.
Popular tools:
- TensorFlow
- PyTorch
- Scikit-learn
Jupyter Notebook: Best for Experimentation
Most ideas start here. The notebook gives you the option to code, plot, and model in one place.
It is your playground if you are learning any machine learning techniques from a tutorial.
Best use cases:
- Testing models
- Visualizing results
Cloud Platforms: Scaling ML Models
But as you develop more advanced models, having access to a local computer won’t be sufficient anymore. Using cloud computing services such as AWS, Google Cloud, or Azure will allow you to increase performance and deploy applications more easily.
Best for:
- Deployment
- Scalability
ML Model Development Is Iterative, Not Linear
One of the most popular myths about machine learning is the belief that it is a linear process. In fact, machine learning is a cycle.
Data is gathered, models are trained, and they are evaluated, and then you start all over again. Perhaps the data quality is not sufficient. Maybe the selected features are flawed. Maybe the model itself is overly complex.
When teams build ML models, they constantly iterate. The same goes for monitoring deployed models and updating them with new data.
Machine learning is a cycle rather than a linear process.
Common Mistakes Beginners Make When Building ML Models
Beginners often focus too much on algorithms and not enough on fundamentals. This leads to avoidable mistakes.
One major issue is ignoring data quality. Another is overfitting, where the model performs well on training data but fails in real scenarios. Choosing the wrong model type is also common.
Typical mistakes:
- Poor data quality
- Overfitting
- Wrong model selection
How Real Companies Build ML Models
Real companies don’t handle ML as a solo task; it’s a collaborative effort. Data engineers, data scientists, and ML engineers work together to create scalable systems.
Instead of isolated experiments, companies use pipelines that automate data flow, training, and deployment. This approach is often called MLOps.
When organizations build ML models, they focus on reliability, scalability, and continuous improvement. Models are monitored in real time, retrained regularly, and integrated into business workflows.
ML is no longer just experimentation; it’s infrastructure.
The Future of ML Model Development
The future of machine learning is moving toward automation and accessibility. Tools like AutoML are reducing the need for manual tuning, while AI-assisted development is speeding up workflows.
Soon, building models will become faster and more intuitive. But that doesn’t mean expertise will become irrelevant.
Even as tools evolve, the ability to understand problems and think critically will remain essential when you build ML models.
Building ML Models Is a Skill, Not a Step List
If there’s one thing to remember, it’s this: machine learning isn’t about following steps; it’s about thinking clearly.
Yes, tools and frameworks make things easier. But the real skill lies in understanding data, defining problems, and iterating intelligently.
The best developers don’t just build ML models; they refine them, question them, and improve them continuously.
Because in the end, outstanding models aren’t built by process alone; they’re built by insight.
Frequently Asked Questions
How long does it take to build an ML model?
It depends on the complexity of the problem and data availability. A simple model can take hours, while production-level systems can take weeks or months.
Do I need profound math knowledge to build ML models?
Basic understanding helps, but you don’t need advanced math to start. Practical experience matters more initially.
Which programming language is best for ML?
Python is the most widely used due to its libraries and ease of use.
What is the hardest part of ML model development?
Understanding the problem and preparing the data, these are often harder than modeling itself.
Can beginners follow this machine learning model guide?
Yes, but focus on practice. Reading alone won’t help; you need to build and experiment consistently.
Disclaimer: BFM Times acts as a source of information for knowledge purposes and does not claim to be a financial advisor. Kindly consult your financial advisor before investing.







{kind=link}