


AI systems frequently have to interpret the data that is presented in the form of sequences, be it sentences, speech indicators, or stock market dynamics. Traditional neural networks process information separately; that is, they do not memorize past information easily when information is processed. This shortcoming brought about the necessity to have another model that is specific to sequential data.
- Why Sequence Data Requires Specialized Neural Networks
- How Recurrent Neural Networks Work
- The Architecture Behind RNN Models
- Understanding LSTM Networks and Advanced RNN Models
- Real-World RNN Applications
- Natural Language Processing
- Speech Recognition
- Predictive Text
- Financial Forecasting
- Video and Gesture Recognition
- Strengths and Limitations of Recurrent Neural Networks
- Conclusion
Recurrent Neural Networks Recurrent neural networks are a form of neural network architecture that is capable of processing information sequentially and retaining the previous input. Recurrent neural networks can use past data to comprehend context and trends through internal memory storage. Due to this capability, natural language processing, speech recognition, and time-series forecasting are a few examples of areas of application.
Related: Convolutional Neural Networks (CNN) Explained
Why Sequence Data Requires Specialized Neural Networks
Most datasets in the real world are sequential, i.e., the order of information is important. In the processing of a sentence, the meaning of a word may tend to rely on the preceding words. In the same way, to be able to forecast the price of stock tomorrow, one has to go through past trends.
The classical neural networks consider all inputs as independent, a factor that poses a challenge when sequential data is being analyzed. These models find it difficult to perform tasks like these without recalling what they have learned before, like:
- Language translation
- Speech recognition
- Music generation
- Stock market prediction
For instance, in a sentence like “She went to the bank to deposit money,” the word “bank” refers to a financial institution. In another sentence like “He sat near the riverbank,” the meaning changes entirely. Understanding this difference requires remembering earlier words in the sentence.
This challenge resulted in the creation of sequence models in AI, which are created to handle information in which context and order are paramount. One of the most famous sequence modeling methods in deep learning is the recurrent neural network.
How Recurrent Neural Networks Work
The fundamental concept of RNN deep learning is that when new input is being processed, the network should remember previous inputs. In contrast to the traditional neural networks, which process information once, recurrent neural networks are characterized by loops, which provide the possibility of information persistence over several steps.
An RNN process also involves three primary components in each of its steps:
- Input data: the present element in the sequence.
- Hidden state: information saved in the past.
- Output: prediction or the result of the network.
The concealed state serves as a memory that brings out context to the sequence.
As an illustration, in the word-by-word analysis of a sentence, the network becomes fed each word with information stored about the words that have already been read or processed. This enables the model to have some knowledge of words and to detect meaningful patterns.
In absolute language, recurrent neural networks resemble a reader that reads a story. The reader recalls previous sections of the story as every sentence is read, which adds value to the reader in grasping the subsequent section.
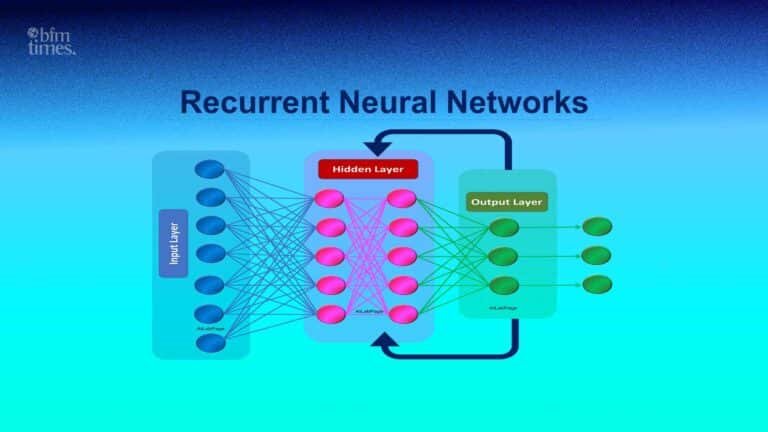
The Architecture Behind RNN Models
The Recurrent Neural Networks architecture is defined in such a way that it facilitates sequential processing of data. The model repeats the same operations for every element in a sequence instead of transmitting the information through a network only once.
The fundamental framework normally consists of:
1. Input Layer
The current piece of data (e.g., a word in a sentence or a value in a time series) is fed into the input layer.
2. Hidden State Layer
The network memory is stored within this layer. It takes the present input together with the past hidden state in order to generate a new memory.
3. Output Layer
The hidden state is used to provide predictions at the output layer.
The procedure is repeated in the course of several time steps:
- Step 1: Processing of input and storing in the hidden state.
- Step 2: The next input is fed into memory.
- Step 3: The memory keeps on updating as the sequence moves on.
Since the network parameters are reused in every step, recurrent neural networks can be used to process sequences of different lengths.
They are especially convenient in those tasks that need neural networks for NLP, as the language used can differ significantly in length and composition.
Suggested: ICO vs IDO: Presale Differences Explained
Understanding LSTM Networks and Advanced RNN Models
Although the recurrent neural networks are a very powerful design, early models had a problem with learning the long-term dependencies. As the sequences get very long, the information from previous steps might be forgotten during the training. This problem is referred to as the vanishing gradient problem.
In order to cope with this issue, researchers came up with sophisticated architectures.
LSTM Networks
LSTM networks (Long Short-Term Memory networks) are a better form of RNN models. They have specialized memory cells that govern the flow of information in the network.
These cells contain mechanisms known as gates, which determine:
- What information to keep
- What information to forget
- What new information to add
Due to this architecture, the LSTM networks are capable of recalling significant patterns in longer sequences.
Gated Recurrent Units (GRU)
The other variation is the Gated Recurrent Unit (GRU). GRUs reduce the LSTM architecture, yet they continue to perform effectively on several tasks.
Both LSTM and GRU models are commonly used in the modern world since they enhance the stability and learning capacity of recurrent neural networks.
Real-World RNN Applications
Recurrent neural networks are important in most contemporary AI. Sequence analysis makes them useful in various industries.
Examples of common uses of RNN include:
Natural Language Processing
Many neural networks for NLP are based on RNN structures to process language data in many instances.
Examples include:
- Text generation
- Chatbots
- Sentiment analysis
- Machine translation
RNN models process words sequentially, and hence they are able to comprehend context and grammar.
Speech Recognition
Speech recognition systems and voice assistants are extremely dependent on sequence modeling. The recurrent neural networks are used to process audio signals with time in order to encode spoken language into literature.
Predictive Text
RNN models can be used in smartphones and messaging platforms to predict the next word as it is typed. The system can guess what is next to be typed by the user by analyzing the past words in the sentence.
Financial Forecasting
Finance is characterized by time-series data. RNN models have the ability to analyze historical price patterns in order to assist in a forecast of what will happen in the market in the future.
Video and Gesture Recognition
Video data are composed of frame sequences. Recurrent neural networks are used to determine the motion patterns and recognize the actions in a series of frames.
Strengths and Limitations of Recurrent Neural Networks
Recurrent neural networks have a number of benefits in the case of sequential data.
Strengths
Contextual learning
The RNNs learn connections among items in a series.
Elastic sequence processing.
They are able to analyze sequences of different lengths.
Excellent language performance.
RNN architectures have long been used in many NLP systems.
Also Read: Dogecoin Explained Price Use Cases & Future
Limitations
Although they have strengths, recurrent neural networks have certain challenges as well.
Slow training
Sequential processing may be more time-consuming to train than other structures.
Vanishing gradient problem
The previous versions faced the problem of learning long-range dependencies.
Newer models compete.
In other uses, new transformer-based architectures have substituted classical RNN models.
Despite these shortcomings, recurrent neural networks are still a significant concept in deep learning and sequence modeling.
Conclusion
Recurrent neural networks are an effective neural network architecture that can analyze sequential information. They are also able to store information of previous inputs as they analyze new data, unlike traditional models, and are therefore suitable for tasks that require language, speech, and time-series analysis.
Recurrent Neural Networks are able to learn the context and patterns through time using internal memory mechanisms and recurring connections. LSTM networks and GRUs are even more advanced architectures, which have enhanced their long-sequence capabilities.
During the era of emerging newer models of deep learning, recurrent neural networks remain fundamental in artificial intelligence studies and numerous real-world machine learning systems.
Disclaimer: BFM Times acts as a source of information for knowledge purposes and does not claim to be a financial advisor. Kindly consult your financial advisor before investing.
What is a Recurrent Neural Network RNN?
A Recurrent Neural Network RNN is a deep learning model designed to process sequential data by remembering previous inputs.
How do Recurrent Neural Networks work?
RNNs use feedback loops that allow information from earlier steps in a sequence to influence future predictions.
Where are Recurrent Neural Networks commonly used?
RNNs are commonly used in speech recognition, language translation, text generation, and time series forecasting.









{kind=link}